
Reference: https://arxiv.org/pdf/1905.04899.pdf
Presentation slides: slideshare ppt
CutMix
The Deep ConvNets show great performance on various computer vision tasks such as classification, object detection, semantic segmentation, and video analysis. For these tasks, many data augmentation and regularization techniques have been proposed to increase performance.
In particular, to prevent overfitting, co-adaptation, and excessively relying on the small portion of intermediate activations or small region on input images, random feature removal regularization techniques have been proposed including dropout and regional dropout which erases random spatial regions on the input image. The empirical studies showed that these regularization methods do show improved generalization and localization.
Yet, the author suggests that such techniques in fact greatly reduce the proportion of informative pixels on trainig images which is considered as a severe conceptual limitation.
What is the paper trying to address?
The paper is asking how to maximally utilize the deleted regions while preserving generalization and localization effects using regional dropout?
The above question is addressed by an data augmentation method called CutMix which replaces the deleted regions with a patch from another image. Then what about the labels? The ground truth labels are also mixed proportionally to the number of pixels of the combined two images.
Consequently, utilizing the deleted(replaced) regions, there’s no information loss during training like plain regional dropout. Another effect of CutMix is that it enhances the localization ability because the replacement of a patch requires the learner to identify the object from a partial view.
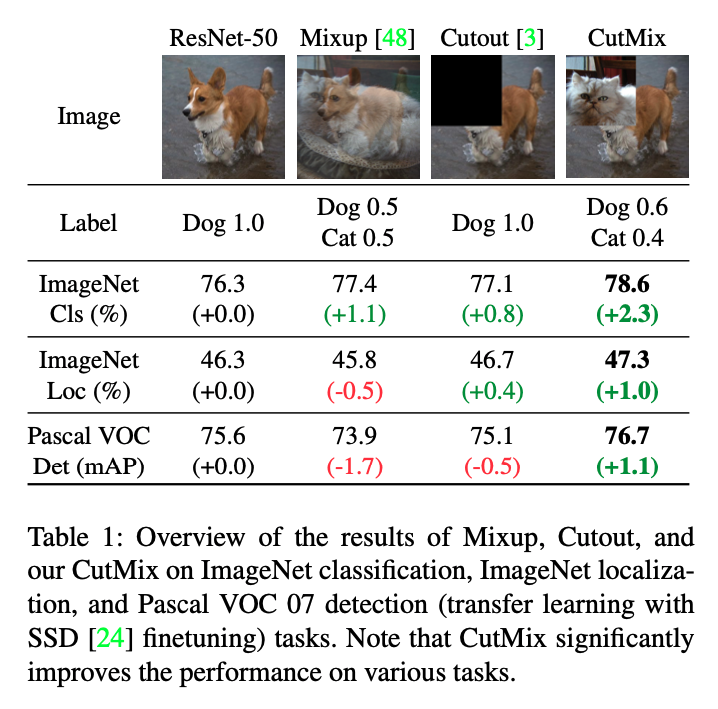
CuxMix shows similarity with Mixup as they both mix two images by interpolating both the image and the label. However, Mixup samples are more “unnatural” as you can see the co-presence of dog and cat(I personally think CutMix samples look weird too..). Although Mixup and Cutout give better performance, they don’t do really well for ImageNet classification and object detection tasks. Meanwhile, CutMix shows improved performance for all the tasks.
- CutMix is applied to a baseline classifier on CIFAR-10 and achieved \(14.47\%\) top-1 error. Also, ResNet-50 and ResNet-101 show \(+2.28\%\) and \(1.70\%\) classification accuracy improvements with CutMix.
- Cutmix also enhances the performnace of weakly-supervised object localization(WOL) task.
- CutMix achieves \(+1 mAP\) increased performance on detection for Pascal VOC and \(+2 BLEU\) scoresfor image captioning performance on MS-COCO dataset.
- Lastly, CutMix enhances the model robustness and alleviates the over-confidence issue.
Comparison with other techniques
Regional Dropout
Regional dropouts remove random regions in images and indeed show better generalization performance. While CutMix is similar to regional dropout, the key difference is that CutMix remove and replace with a patch from another image.
Synthesizing training data
A synthesizing technique such as Stylizing ImageNet suggests to focus more on shape than texture. Unlike this technique, CutMix requires only trivial additional cost for training while generating new samples.
Mixup
Mixup samples sometimes confuse the model by introducing locally ambiguous and unnatural images. Some other variants of Mixu perform feature-level interpolation but they lack localization ability and transfer-learning performance. On the other hand, CutMix enjoys performance boost for classification, localization, and transfer learning tasks.
Complementary to other methods
CutMix goes well along with weight decay, batch normalization, and adding noises. CutMix can be complementary to those methods since CutMix only operates on data level.
CutMix Algorithm
Notations
- \(x \in \mathbb{R}^{W * H *C}\): training image
- \(y\): label
- \((x_A,y_A)\), \((x_B,y_B)\): training samples before CutMix
- \((\tilde{x},\tilde{y})\): New training sample after CutMix
CutMix Operation
\(\tilde{x}=M \odot x_A + (1-M) \odot x_B\) \(\tilde{y}=\lambda y_A + (1-\lambda)y_B\)
where
- \(M \in {\{0,1\}}^{\{W*H\}}\) denotes a binary mask indicating where to drop out and fill in from two images.
- \(1\) is a binary mask filled with ones.
- \(\odot\) is element-wise multiplication.
- \(\lambda\) is the combination ratio between two data and is sampled from the uniform distribution \(U(0,1)\).
- The binary mask \(M\) is obtained by sampling the bounding box coordinates \(B = (r_x,r_y,r_w,r_h)\) referring to the cropped regions on \(x_A\) and \(x_B\). The region \(B\) in \(x_A\) is removed and replaced with the other patch cropped from \(B\) of \(x_B\).
For \(r_x, r_y, r_w, r_h\), \(r_x \sim U(0,W),\ r_w = W\sqrt{1-\lambda}\) \(r_y \sim U(0,H),\ r_h = H\sqrt{1-\lambda}\) making the cropped area ratio \(\frac{r_wr_h}{WH}=1-\lambda\).
- From the cropped region, the binary mask \(M \in {\{0,1\}^{W*H}}\) is filled with \(0\) within the bounding box \(B\), \(0\) otherwise.
In each training iteration, \((\tilde{x},\tilde{y})\) is generated by combining randomly selected two samples in a mini-batch by equations (2) and (1).
CutMix on Class Activation Map
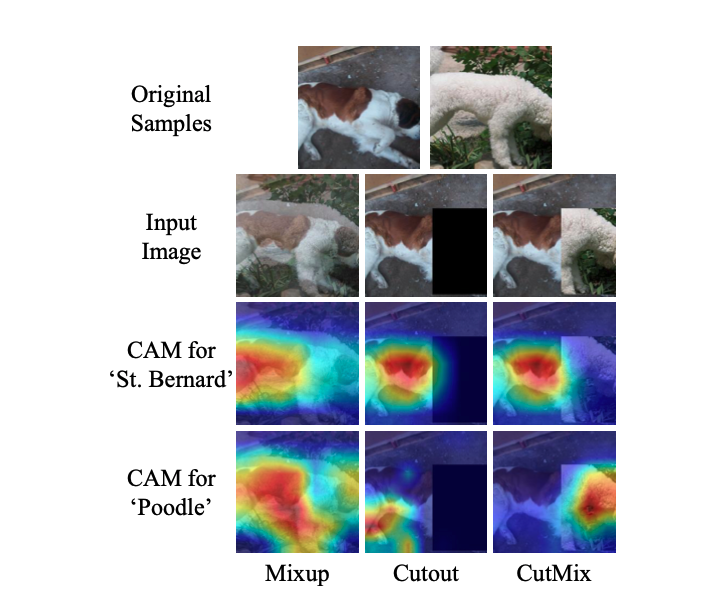

The above is the class activation map for Mixup, Cutout, and CutMix. For fair comparison, the vanilla ResNet-50 model is used.
While Cutout focuses on less discriminative parts such as belly, it loses informative pixel values. Mixup fully uses the pixels, it introduces unnatural artifacts and confuses the model which object to choose. The author hypothesizes that this confusion results in suboptimal performance on classification and localization.
On the other hand, CutMix successfully localize the two object classes as demonstrated in the above figure.
Validation Error
- ResNet-50 is used for ImageNet Classification
- PyramidNet-200 is used for CIFAR-100 Classification
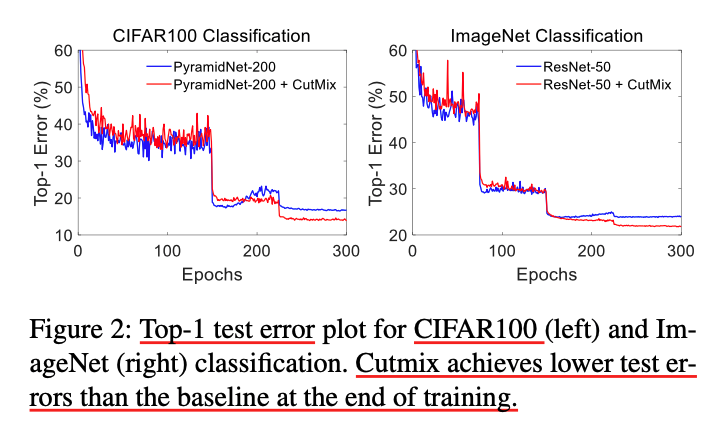
The graph shows that applying CutMix results in lower validation error at the end of the training.
Comparison with other methods for Classification
For fair comparision, the standard data augmentation setting such as resizing, cropping, and flipping. The time to reach convergence for CutMix requires a higher number of training epochs.
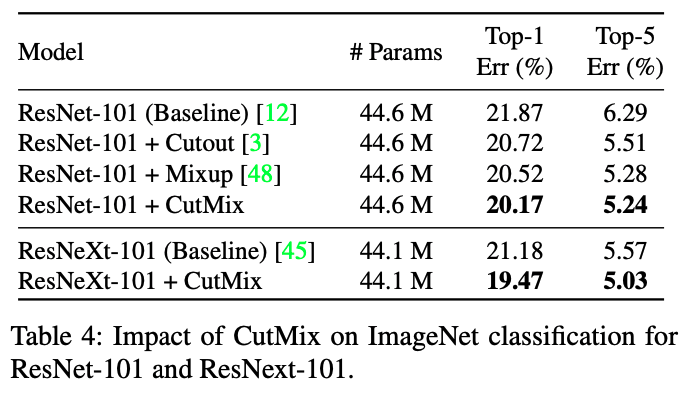
ImageNet
All the models were trained with 300 epochs with lr=0.1, lr decay 0.1 at epochs 75,150,225, batch size=256, \(\alpha=1\).
CIFAR-10
Mini-batch size of 64, 300 epochs, 0.25 learning rate, decay rate 0.1 at 150 and 225 epochs.
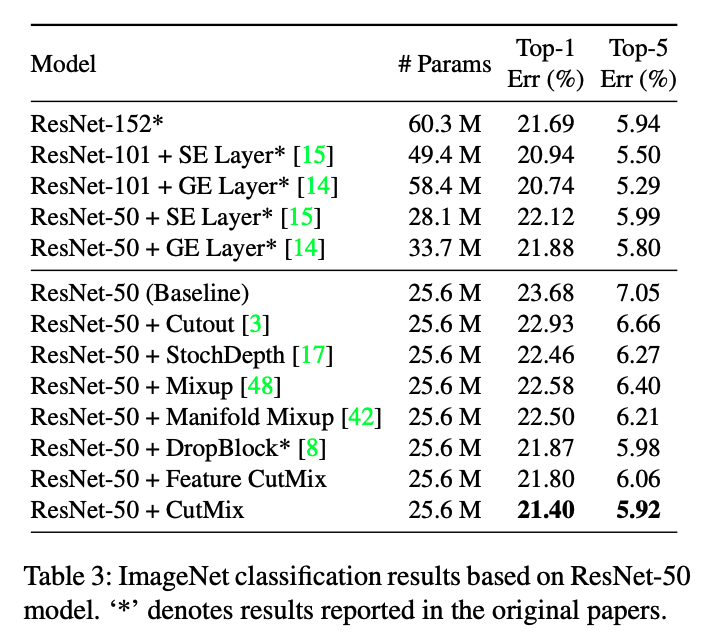
vs Architectural Improvements
CutMix imporves the performance by \(+2.28\%\) while increased depth from ResNet-50 to ResNet-152 increases \(+1.99\%\). Along with better performance gain, CutMix requires much less memory or computational cost.
CutMix Pseudo-code

Conclusion
CutMix consistenly improves performance on image classification, localization, semantic segmentation, and object detection. Also, using CutMix-ImageNet pretrained model as the initialized backbone of the object detection and image captionining brings performance improvements as well. For ImageNet, ResNet-50 and ResNet-101 with CutMix show \(+2.28\%\) and \(+1.70\%\) top-1 accuracy. For CIFAR-10, CutMix significantly improves the baseline architectures such as PyramidNet-110 and ResNet-110.