
Intro
Memory는 volatile(휘발성)이기 때문에 데이터를 영구히 보관하기 위해서는 disk와 같은 2차 저장장치가 필요하다.
이 포스트에서는 disk의 효율적인 관리를 위해 사용되는 disk scheduling 기법과 저전력 disk 관리 기법에 대해 알아본다.
1. Disk의 구조
Logical block (논리블록)
- Disk 외부에서는, disk를 일정한 크기의 저장공간들로 이루어진 1차원 배열로 취급한다. 이러한 저장공간 unit을 logical block이라고 한다.
- Disk에 데이터가 저장 및 입출력이 될때에도 logical block단위로 저장/전송된다.
- Logical block에 저장된 데이터에 접근하려면 배열처럼 index number을 disk에 전달해야 한다. 그러면 disk controller가 해당 logical block이 저장된 물리적 위치를 찾아 I/O 작업을 수행한다.
- Sector
- 각 logical block이 저장되는 disk내의 물리적인 위치를 sector(섹터)라고 부른다.
- 즉, logical 하나가 sector 하나랑 1:1 매핑된다.
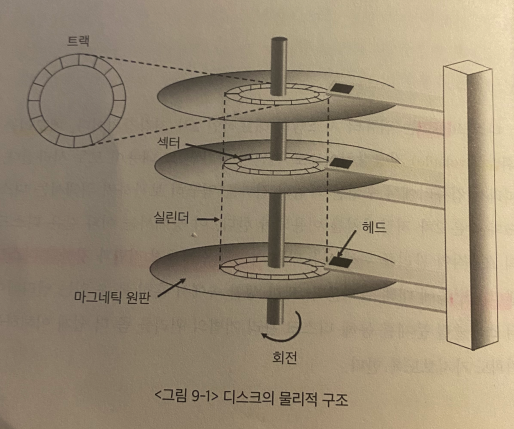
- Disk는 하나/여러개의 마크네틱 원판으로 구성된다
- 각각의 원판은 여러개의 track (트랙)으로 나뉜다
- 각 트랙은 여러개의 sector(최소단위) 으로 나뉜다
- 여러개의 원판에서 상대적 위치가 동일한 track들의 집합을 cylinder라고 한다.
- ex) Sector 0: outermost cylinder, 1st track, 1st sector이다.
- 데이터를 read/write하기 위해서는 arm이 해당 sector가 위치한 cylinder으로 이동한후, 원판이 rotate하여 disk head가 sector 위치에 도달한다.
2. Disk Scheduling
Disk에 대한 access time (접근 시간)은 어떻게 구할까?
- Disk access time의 3가지 종류
- Seek Time (탐색시간)
- Disk head를 해당 cylinder 위치로 이동시키는 시간 (데이터가 원판 안쪽/바깥쪽에 있는지에 따라 헤드를 움직이는 시간)
- Rotational Latency (회전지연시간)
- Disk가 회전해서 데이터가 head 위치에 도달하는데 걸리는 시간
- Transfer Time (전송시간)
- Sector이 head 위치에 도달한후, 데이터를 실제로 읽고 쓰는데 소요되는 시간
- Seek Time (탐색시간)
Disk의 입출력 효율을 높이기 위해서는 disk access time을 줄여야 한다.
Access time을 줄이기 위해서는 seek time, rotational latency, transfer time을 줄여야 하는데,
Rotational latency와 transfer time은 수치가 작을 뿐 아니라 통제하기 힘들어서 무시한다.
결국 seek time을 최소화하는 disk scheduling을 한다.
Disk Scheduling
- 효율적인 Disk I/O를 위해, 여러 sector들에 대한 I/O 요청이 들어왔을때, 이들을 어떠한 순서로 처리할 것인지 결정하는 메커니즘.
Disk scheduling의 가장 중요한 목표는 seek time을 줄이는것, 즉 disk head의 이동거리를 최소화 하는것이다.
1) FCFS Scheduling
FCFS(First Come First Server) 스케쥴링은 disk에 먼저 들어온 요청을 먼저 처리하는 방식이다.
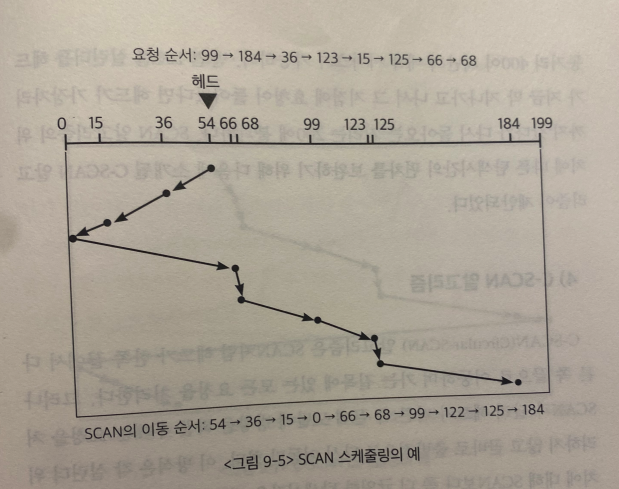
예를 들어, 다음과 같은 cylinder 위치에 입출력 요청이 들어왔다고 하자 (disk에 총 200개 cylinder이라고 가정)
99 184 36 123 15 125 66 68
만약 disk head가 처음에 54번 cylinder에 있을 경우에 head는
- 54 -> 99
- 99 -> 184
- …
와 같이 이동하게 된다. 따라서 총 이동거리를 계산하면 644가 된다.
FCFS은 효율성이 매우 떨어진다.
- I/O 요청이 만약 계속 현재 head 위치보다 먼 곳에 위치하면 seek time이 매우 늘어난다
- 극단적으로 disk의 한쪽 끝과 다른 한쪽 끝에서 반복적으로 요청이 들어오면 최악의 경우가 된다.
SSTF(Shortest Seek Time First) Scheduling
SSTF 스케쥴링은 head의 현재 위치로부터 가장 가까운 위치에 있는 요청을 먼저 처리하는 방식이다.
만약 99, 184, 36, 123, 15, 125, 66, 68 cylinder 위치에 요청들이 들어왔고, head의 위치가 현재 54이라면,
- 54에서 제일 가까운
66으로 이동 66->68- …
그러면 총 이동거리는 236이 된다.
SSTF의 한계
- FCFS보단 낫지만 starvation현상이 발생할 수 있다
- 현재의 head위치에서 가까운곳에서 지속적으로 요청이 들어온다면, head로부터 먼곳의 애들은 무한히 기다려야 할수도 있다.
SCAN Algorithm
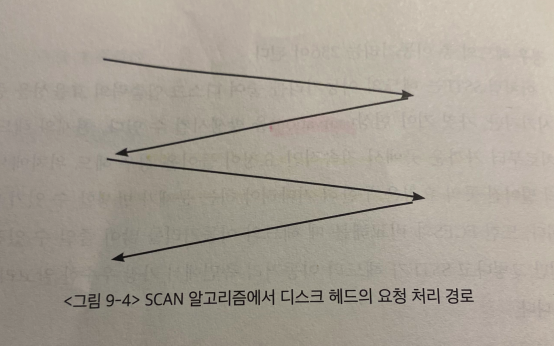 SCAN 알고리즘은 head가 disk 원판 안쪽 끝과 바깥쪽 끝을 왕복하며, 그 경로에 존재하는 모든 요청을 처리한다.
SCAN 알고리즘은 head가 disk 원판 안쪽 끝과 바깥쪽 끝을 왕복하며, 그 경로에 존재하는 모든 요청을 처리한다.
- 즉, disk 요청에 상관없이, head는 정해진 방향으로 이동하면서 길목에 있는 녀석들을 다 처리하는것이다.
SCAN 알고리즘은, 엘리베이터에서 사용하는 스케줄링 알고리즘과 유사하다. 엘리베이터는 한 방향으로 이동하면서 진행 방향으로 가는 승객에 있으면 다 태운다. 그리고 그 방향으로 요청이 없으면 방향을 바꾸어서 반복한다.
따라서, SCAN 알고리즘은 elevator algorithm이라고 불리기도 한다.
SCAN 알고리즘의 장/단점
- 장점: SCAN 알고리즘에서는, FCFS처럼 불필요한 head의 움직임이 발생하거나, starvation현상이 발생하지 않기에, 효율성과 형평성을 모두 만족한다.
- 단점: 하지만, 모든 cylinder 위치의 기다리는 시간이 공평한 것은 아니다. 제일 안쪽이나 제일 바깥쪽 보다는 가운데 위치가 기다리는 평균시간이 더 짧다.
- 0 ~ 199번 cylinder가 있다고 할때, 헤드가 가장자리인 0번 혹은 199번 실린더를 지금 막 지나가고 나서, 해당 지점에 요청에 들어온다면 헤드의 이동거리가 400이 지나고 난 후에야 서비스가 가능하다.
- 이 문제를 보환하기 보완하기 위해 C-SCAN Algorithm이 제안되었다.
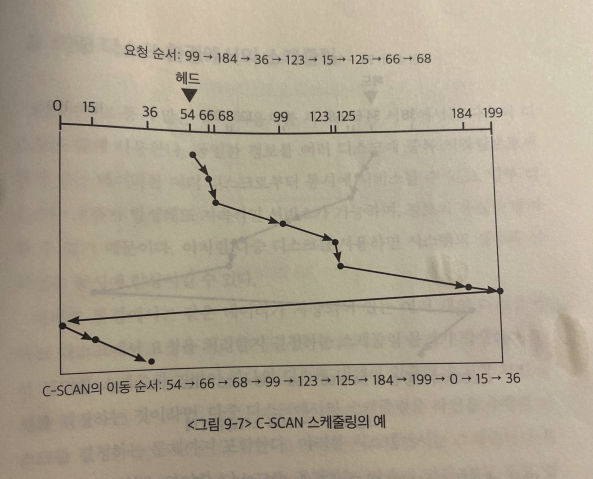
C-SCAN Algorithm
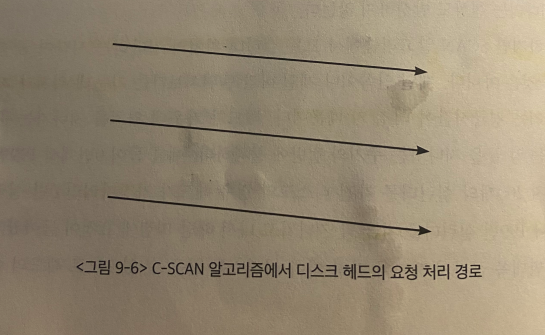 C-SCAN Algorithm (Circular-SCAN)은 SCAN처럼 헤드가 한쪽 끝에서 다른 쪽 끝으로 이동하며 가는 길목에 있는 요청을 다 처리한다는 점은 동일하다.
C-SCAN Algorithm (Circular-SCAN)은 SCAN처럼 헤드가 한쪽 끝에서 다른 쪽 끝으로 이동하며 가는 길목에 있는 요청을 다 처리한다는 점은 동일하다.
다른 점은, 헤드가 한 쪽 끝에 도달해 다른 쪽으로 돌아갈때, 요청을 처리하지 않고 곧바로 출발점으로 이동한다.
- 이 방식은, head의 이동거리는 조금 더 길어지지만, 탐색시간의 편차를 줄일 수 있다.
LOOK과 C-LOOK 알고리즘
LOOK 알고리즘
SCAN 알고리즘에서는, 요청의 존재 여부와 상관없이 헤드가 무조건 disk의 한쪽 끝에서 다른 쪽 끝으로 이동한다.
반면 LOOK 알고리즘은 head가 한쪽 방향으로 이동하지만, 그 방향에 더이상 요청이 없으면 방향을 반대로 바꾼다.
C-LOOK 알고리즘
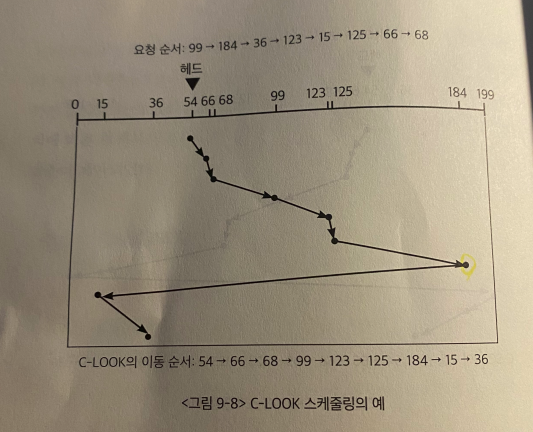
전방에 요청이 없을때 방향을 바꾸는건 LOOK이랑 유사하지만, 한쪽 방향으로 이동할 때에만 요청을 처리한다는 점에서는 C-SCAN과 유사하다.
- 위의 그림에서 head가 184번 cylinder에서 더 이상의 요청이 없으므로 199번 까지 가지않고 즉시 방향을 바꾼다.
- 또한 head가 반드시 0번까지 가는것이 아니라 요청이 존재하는 가장 낮은 cylinder 번호까지만 간다.
3. 다중 디스크 환경에서의 스케쥴링
- 수많은 사용자들이 있는 서버에는 다수의 disk를 함께 사용한다.
- 동일한 정보를 여러 disk에 중복 저장함으로써 다음과 같은 이점을 얻을 수 있다.
- 인기있는 데이터를 여러 disk로부터 동시에 서비스
- 오류가 발생해도 지속적인 서비스 유지
- 정보의 유실을 방지
이처럼 다중 디스클크를 사용하면 시스템의 성능과 신뢰성을 향상시킬수 있다.
다중 디스크 스케쥴링 이런 환경에서 여러개의 disk중 어느 disk에서 요청을 처리해야 하는 scheduling문제가 발생한다.
- 하나의 disk내에서 스케쥴리오가 더불어, 어느 disk에서 작업을 수행할지도 고려해야한다.
스케쥴링의 목표에 따라 disk를 선택하는 기준이 달라진다
- Seek time을 줄이는게 목표라면, 데이터와 가장 가까운 disk를 선택
- 즉, 각 disk간의 load balancing(부하균형)을 이루도록 스케쥴링 하는것이 중요하다.
- 최근에는 전력 소모를 줄이는 것이 disk 관리의 또 다른 중요한 목표다.
- 모든 disk에 요청을 분산시키기 보다, 일부 disk에 요청을 집중시키고 다른 disk는 정지하는게 더 효과적이다.
4. Disk의 저전력 관리
1) 비활성화 기법
- Disk의 상태는 크게 다음 4가지로 나눌 수 있다.
- Active (활동) - 현재 head가 disk I/O를 수행중
- Idle (공회전) - Disk가 회전 중이지만, disk I/O를 수행하지 않음
- Standby (준비) - Disk 회전 X, 인터페이스는 활성화
- Sleep (휴면) - Disk 회전 X, 인터페이스 활성화 X
- 편의상, active & idle을 활성, standby & sleep을 비활성 상태라 부른다고 가정
- 비활성 -> 활성 상태로 갈때 에어컨 키는것처럼 많은 전력이 소모된다.
- 따라서, 후속 요청까지의 시간 간격이 일정 시간(break-even time)이상일 경우에만 disk를 정지하는게 효율적
- Disk를 비활성화 하는 시점을 결정하는 방법은
- Timeout-based (시간기반)
- Prediction-based (예측기반)
- 과거의 요청 관찰, 다음 idle 구간 예측
- Stochastic-based (확률기반)
- Markov chain등과 같은 통계적 모델 이용
2) 회전속도 조절 기법
- Disk 전력 소모를 줄이기 위해 RPM (rotations per minute)을 가변적으로 조절
- Workload의 특성을 활용해 회전속도를 조절하려는 시도
3) Disk의 배치 기법
- Disk의 용량은 계속 증가하지만, 접근 속도는 딱히 발전이 없다.
- Disk내에 데이터의 복제본을 많이 만들어, head 위치에서 가까운 복제본에 접근하도록 하는 FS2 file system(free space file system) 제안됨
4) Buffer caching 및 사전인출 기법
- 미래에 요청될 데이터를 어느 정도 예측할 수 있으면, disk가 활성 상태일때, head 위치로부터 가까운 데이터를 prefetching (사전인출)하는 방법도 있다.
5) 쓰기 전략을 통한 저전력 disk 기법
- 저장장치에 대한 write strategy (쓰기 전략)을 통해 전력 소모를 줄이는 기법도 있다.
- 대상 disk가 비활성 상태일때는 disk 쓰기를 하지않고 있다가, 활성 상태로 바뀌면 그때 쓰는 방식이다.