
Table of Contents
- 1. Variables are not boxes, but labels
- 2. Identity, Equality, and Aliases
- 3. Choosing between
==andis - 4. The Relative Immutability of Tuple
- 5. Shallow vs Deep Copy
- 6. Function Parameters as References
- 7. Mutable Types as Parameter Defaults: Bad Idea
- 8.
delkeyword and Garbage Collection
1. Variables are not boxes, but labels
- Variables are not boxes, but merely labels attached to objects.
b = adoes not copy the contents of a into b, but attaches the label b to the object that already has the label a.1 2 3 4 5 6
a = [1, 2, 3] b = a a.append(4) print(b) # Result: [1, 2, 4, 5]
- Instead of word “assignment”, it’s better to say that
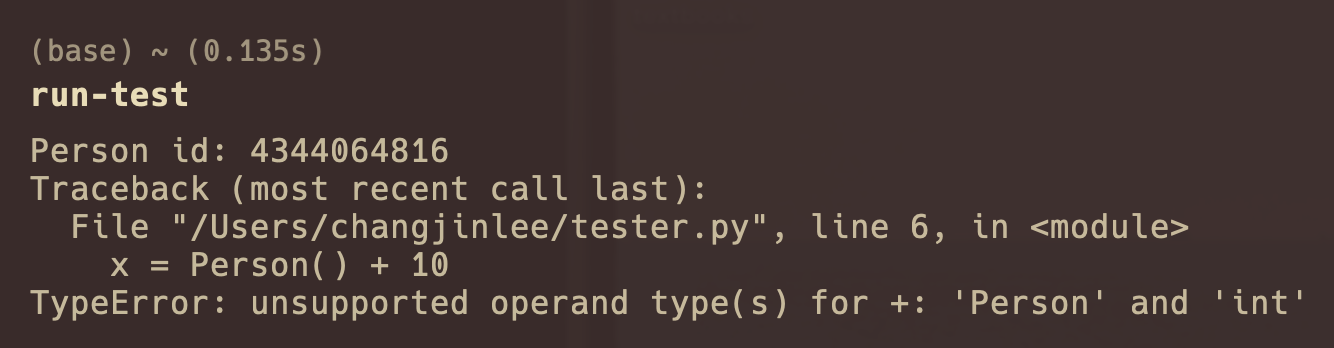
x = ...binds the namexto the whatever object created in the right-hand side. - An object is created before the variable is bound to it. See person id is printed then the error occurs so the variable
xis not even created.1 2 3 4 5
class Person: def __init__(self): print(f"Person id: {id(self)}") x = Person() + 10
![Alt text]()
- Because variables are just labels, an object can have multiple labels bound to it. This is called aliasing.
2. Identity, Equality, and Aliases
1
2
3
4
5
6
7
8
9
jason = {"name": "Jason Lee", "age": 27}
jack = jason
peter = {"name": "Jason Lee", "age": 27}
print(jason == jack) # Equality True
print(jason is jack) # Identity True
print(id(jason) == id(jack)) # Same
print(jason == peter) # Equality True
print(jason is peter) # Identity False
jackis an alias forjason. They’re bound to the exact same object. This is whyjason is jackevaluates to true.peterhappens to have the exact same value asjason. They’re bound to completely different objects.id()returns an integer representing an object’s unique identity. This id never changes throughout the object’s life-cycle.id(jason) == id(jack)proves that they’re bound to the same object.
The real meaning of
id()is implementation-dependent. In CPython,id()returns the memory address of the object but it could be something else in other interpreters.- In practice, use
isoperator which compares the object IDs, rather than comparingid().
isoperator compares the object identity, while==operator compares the object values.jason is peteris False, butjason == peteris True since they hold the same value.
Actually
==operator evaluates__eq__special method of the class (in this case, dict)
3. Choosing between == and is
==operator compares values whileisoperator compares their identities- When we write codes, we often care more about values than identities.
- However, when comparing a variable to a singleton, use
isoperator.- The most common case is to check whether the variable is bound to
None. - Another use case is sentinel objects.
- The most common case is to check whether the variable is bound to
isoperator is faster than==as it doesn’t require special methods to evaluate it.a == bis just a syntactic sugar fora.__eq__(b).__eq__is inherited fromobject(base object for all objects) and compares identity. However, most built-in types override this with more meaningful implementations that take values into account.
In most cases, we’re interested in object equality rather than identity. Checking for
Noneis the only common use case we useis. Besides that, always use==
4. The Relative Immutability of Tuple
1
2
3
4
5
tup = (1, 2, [5, 6, 7])
print(id(tup[-1])) # 123456
tup[-1].append(99999)
print(tup) # (1, 2, [5, 6, 7, 99999])
print(id(tup[-1])) # 123456
The identity of the item the tuple contains can never change even if it’s mutated. And this is what really “tuple is immutable” means.
- We know that tuple is an immutable object, holding references to objects.
- If the referenced items are mutable, they may change even if the tuple itself is immutable.
- In other words, immutability does not extend to the referenced objects.
- If all the nested items a tuple is holding are immutable, then the tuple is hashable.
1 2 3 4 5
tup1 = (1, 2, (5, 6)) # all immutable tup2 = (1, 2, [5, 6]) # contains mutable obj print(f"tup1 hashed: {hash(tup1)}") print(f"tup2 hashed: {hash(tup2)}") # error
![Alt text]()

5. Shallow vs Deep Copy
Shallow Copy
Shallow copy is a copy where the outermost container is duplicated, but the copy is filled with references to the same items hold by the original container.
This saves memory and causes no problem if all the items are immutable, but if there’re mutable items, it might cause problems
- 1. Shallow copy by constructor
1 2 3 4 5
l1 = [3, [[1, 2, 3], 44], (7, 8, 9)] l2 = list(l1) # copy by constructor print(l2 == l1) # True print(l2 is l1) # False print(l2[1][0] is l1[1][0]) # True
- We can see that l2 and l1 hold the same value but they refer to different objects
l2[1][0] is l1[1][0]shows that the shallow copy does not copy nested objects.
- 2. Shallow copy by
[:]1 2 3 4 5
l1 = [3, [[1, 2, 3], 44], (7, 8, 9)] l2 = l1[:] # copy by [:] print(l2 == l1) # True print(l2 is l1) # False print(l2[1][0] is l1[1][0]) # True
- 3. Shallow copy by
copyfunction1 2 3 4 5 6 7
from copy import copy l1 = [3, [[1, 2, 3], 44], (7, 8, 9)] l2 = copy(l1) # copy by copy function print(l2 == l1) # True print(l2 is l1) # False print(l2[1][0] is l1[1][0]) # True
Deep Copy
Sometimes we need to make deep copies (i.e. duplicates that do not share references of the nested/embedded objects as well).
The copy modules provides deepcopy function that returns deep copies of arbitrary objects.
1
2
3
4
5
6
7
8
9
10
11
12
class Bus:
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers)
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name)
Let’s look at the effects of shallow copy and deep copy.
Shallow Copy
1
2
3
4
5
6
7
import copy
bus1 = Bus(['Alice', 'Bill', 'Claire', 'David'])
bus2 = copy.copy(bus1)
print(bus1 is bus2) # False
bus1.drop('Bill')
print(bus2.passengers) # ['Alice', 'Claire', 'David']
print(bus1.passengers is bus2.passengers) # True
We can see that bus1 and bus2 are different objects but dropping Bill for bus1 also has an effect on the bus2. Moreover, bus1 and bus2 indeed share the same passengers list.
Deep Copy
1
2
3
4
5
6
7
import copy
bus1 = Bus(['Alice', 'Bill', 'Claire', 'David'])
bus2 = copy.deepcopy(bus1)
print(bus1 is bus2) # False
bus1.drop('Bill')
print(bus2.passengers) # ['Alice', 'Bill', 'Claire', 'David']
print(bus1.passengers is bus2.passengers) # False
On the other hand, using deepcopy makes dropping have no effect on the bus2 object. Bus1 and Bus2 also have different passengers list.
Cyclic Reference
- Making deep copies is not a simple matter. Objects may have cyclic references that would lead to an infinite loop.
1 2 3 4
a = [10, 20] b = [a, 30] a.append(b) print(a)
deepcopyfunction handles this cyclic references gracefully.
6. Function Parameters as References
- The only mode of parameter passing in Python is call by sharing.
- Call by sharing means that each formal parameter of the function gets a copy of each reference in the arguments.
- The result of this mode is that a function may change any mutable object passed as a parameter.
Let’s this how the objects passed as parameters behave for number, list, and tuple.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def f(a, b):
a += b
return a
x = 1
y = 2
print(f(x, y)) # 3
print(x, y) # 1, 2
a = [1, 2]
b = [3, 4]
print(f(a, b)) # [1, 2, 3, 4]
print(a, b) # [1, 2, 3, 4], [3, 4]
t = (10, 20)
u = (30, 40)
print(f(t, u)) # (10, 20, 30, 40)
print(t, u) # (10, 20), (30, 40)
- number
xis unchanged - list
ais changed - tuple
tis unchanged
7. Mutable Types as Parameter Defaults: Bad Idea
- Avoid mutable objects as default values for parameters
1
2
3
4
5
6
7
def f(lst = []):
lst.append(1)
print(lst)
return lst
f() # [1]
f() # [1, 1]
When we execute the first f(), 1 is appended to the empty list and [1] is printed. However, a strange thing happens when we execute the second f(). Instead of [1], we see that [1, 1] gets printed.
- The problem is that each default value is evaluated when the function is defined (i.e. when module is loaded)
- The default values become attributes of the function object
- So if a default value is a mutable object, and you change it, the change will affect every future call.
- We can check the defaults of a function with
f.__defaults__.
8. del keyword and Garbage Collection
In Python, objects are never explicitly destroyed. Instead, when they become “unreachable”, they maybe garbage-collected.
In CPython, the Python interpreter tracks refcount referring to the how many times an object is referenced by. As I’ll talk about later posts, this is related to the infamous GIL(Global Interpreter Lock). When the refcount of an object becomes 0, the object is garbage-collected by the garbage collector and frees up its memory.
An important thing to note about del keyword is that it deletes references, not objects. In other words, del my_obj statement does not always delete the object out of memory, but it de-references the variable named my_obj to the object that it was pointing at. If my_obj happened to be the last reference, then the Python’s garbage collector would delete the object out of memory.
Also, rebinding a variable also decreases the refcount, may leading to the destruction of an object.
1
2
3
4
5
a = [1, 2]
b = a
del a
print(b) # out: [1, 2]
b = [3] # Object discarded by the garbage collector
In the above example, the list object [1, 2] was referenced by two variables a and b. Then, the reference by a is not deleted and b rebinds itself to another list object. Consequently, the refcount of the original list object reaches 0, causing the destruction of the object.
weakref.finalize
To demonstrate the destruction of an object, we can use weakref.finalize as a callback function to be called when an object is destroyed.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import weakref
def bye():
print("Goodbye..")
a = {1, 2, 3}
b = a
ender = weakref.finalize(a, bye)
print(ender.alive) # out: True
del a # refcount = 1
b = "hello world!" # out: Goodbye...
print(ender.alive) # out: False
We can see that when we rebind the variable b to another object, the refcount of the original set hits 0, triggering the callback function.