
- Introduction
- Challenge Encountered
- Solution - locally cache latest query result
1. Introduction
Girok offers a set of operations to query your tasks effectively.
You can use girok showtask to query all tasks without any filtering.
If you want to query tasks belonging to only a specific category, then you can pass -c <category path> option.
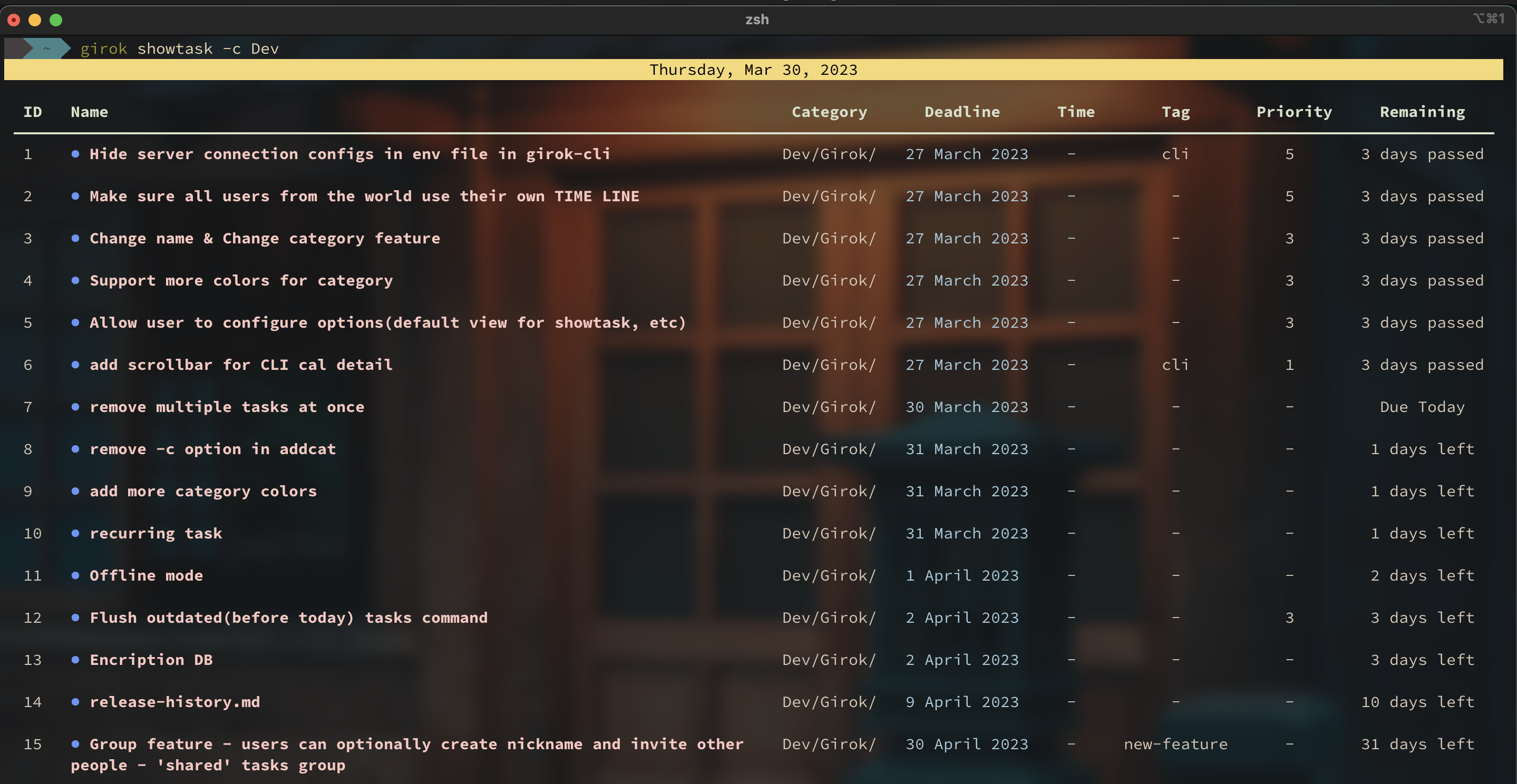
You also have many other filtering options such as date, tag, and priority.
2. The Challenge I Encountered
However, I ran into a challenge when designing the deleting task operation.
The action of deleting a task must be concise and simple because people use CLI services like Girok to save up their valuable time. Also, Users might want to add quite a long task name (more than 30 characters) such as “Break down the abstract idea to smaller ones for tomorrow presentation” so users never want to type task names to delete them.
Hence, I came to a conclusion that deleting a task must be done with some type of taskID so that user can quickly run girok done <taskID>.
But then, there was a dilemma.
Approach #1 - Displaying the original primary keys from the database
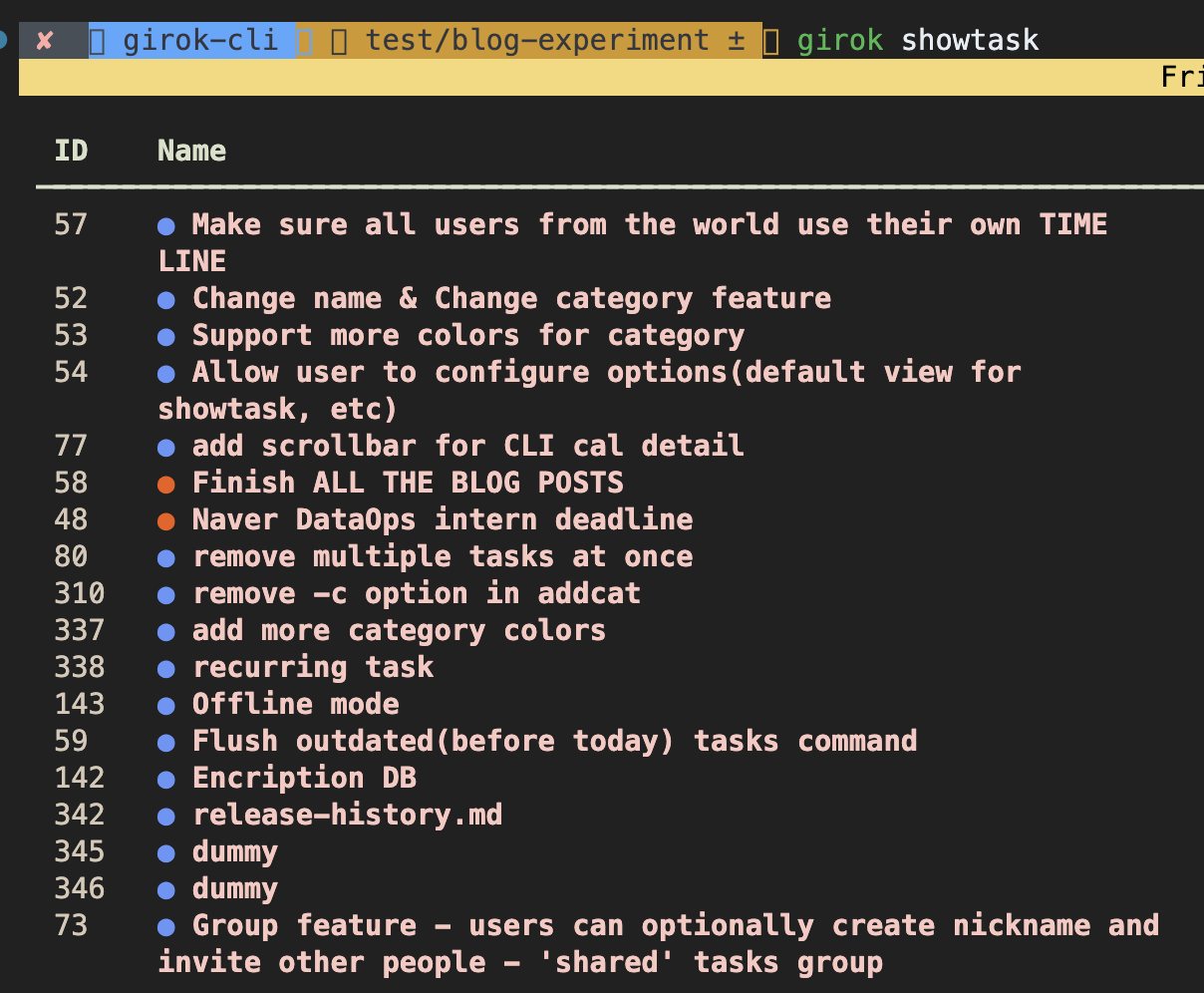
If I just display taskIDs from the remote database when a user runs girok showtask command, then users will see unordered and forever-increasing taskIDs.
This is because as I mentioned in the introduction, users can perform a variety of filtering operations and they are by default sorted by date and priority. Hence, the order of the tasks stored in the database might not sync with what’s shown to the end-users.
Also, when after users delete some tasks, we would have “jumps” in the taskIDs.
Another drawback of this approach is that the taskIDs are forever-increasing unless we manually roll back the primary keys in the database which is not a good strategy.
Lastly, users just don’t want to see random and unordered taskIDs. That just sucks!
Approach #2 - Assign increasing task ids starting from 0 for each task query
Another approach is to assign (fake) increasing task ids starting from 0 for each task query.
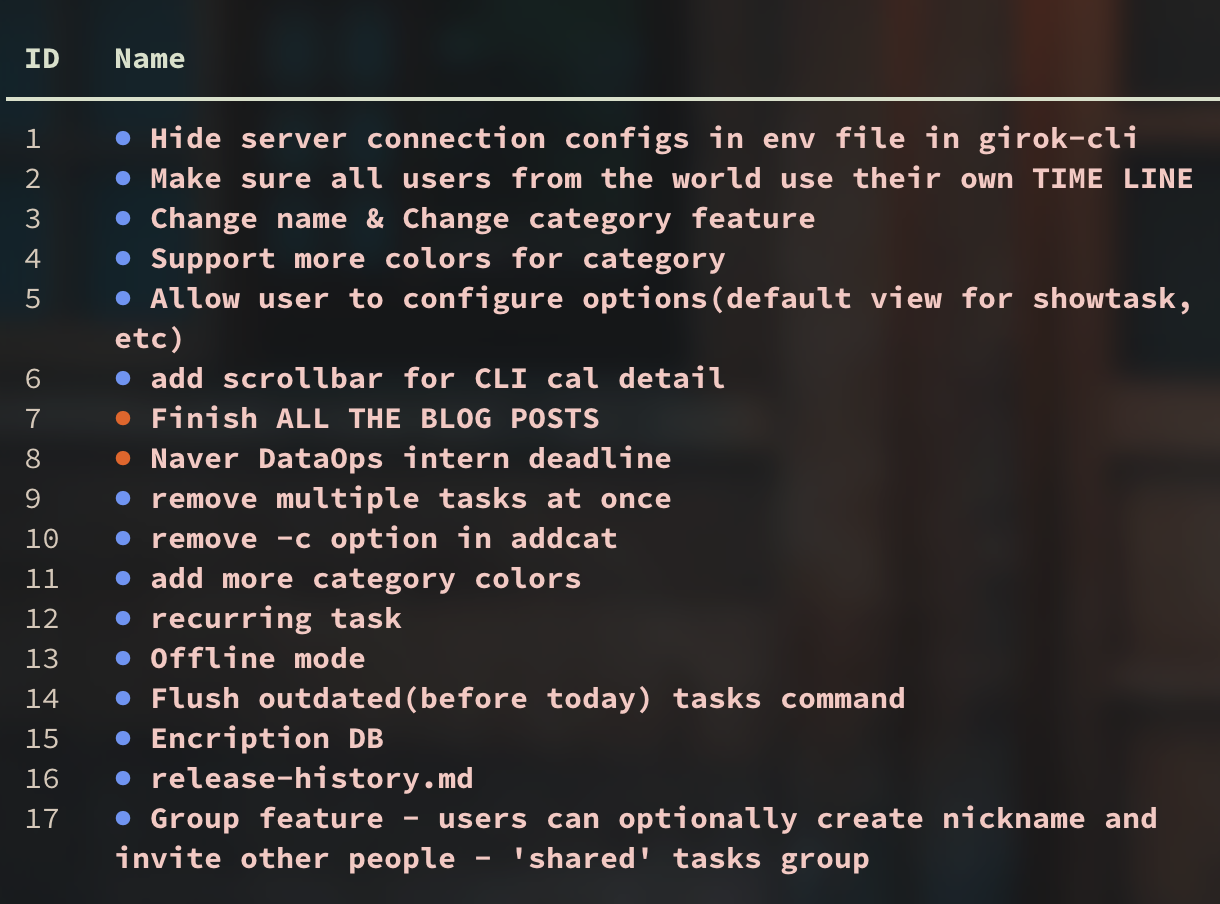
Whatever query users perform, we just simply attach increasing task IDs.
However, this approach has a serious flaw. The same task could have different taskIDs depending on filering options.
Suppose a user performs a query to get tasks only for Dev category.
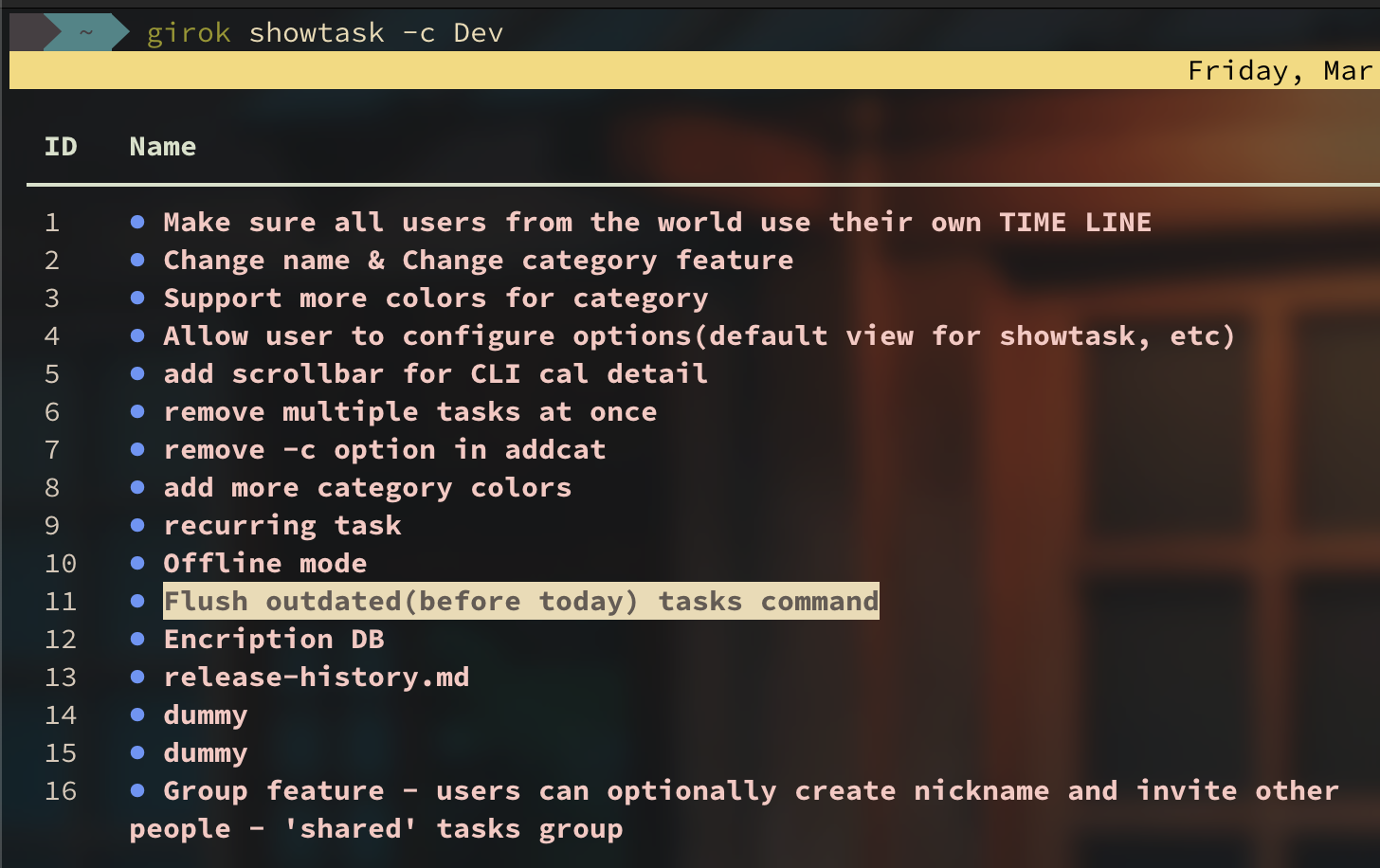
The highlighted task now has taskID 11. However, if the user makes another query to get tasks for Dev category but with only priority 3.
Now, the same task has taskID 4 since the taskID now merely depends on “In which place a specific task appears for each query?”.
Therefore, this example shows that it’s impossible to assign fake increasing taskIDs with which user could pin-point to delete tasks.
3. Solution - Cache the latest query result into local storage
But what if I still want to assign increasing taskIDs starting from 0?
I came to a reasonable and working solution that whenever user performs a query, cache the {fake_id: real_id} mapping into the user’s local storage.
Then, whenever user performs delete operation with a taskID like girok done 10, this “fake” id will be mapped to the real id stored in the cache. This is quite reasonable since it’s most likely that users would perform at least one query to retrieve tasks before they pin-point a specific taskID to delete.
showtask command 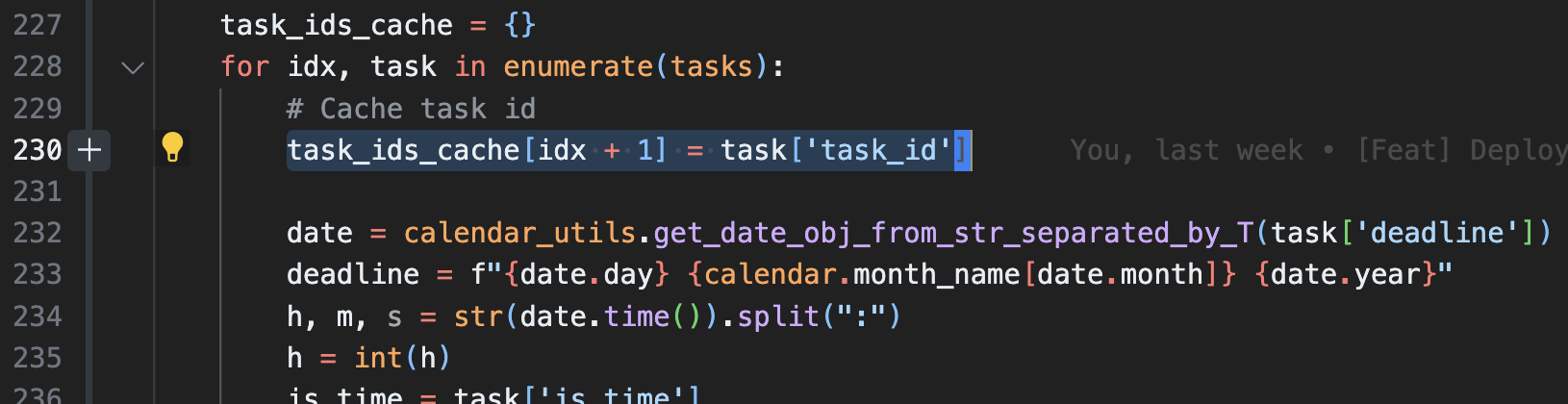

done command 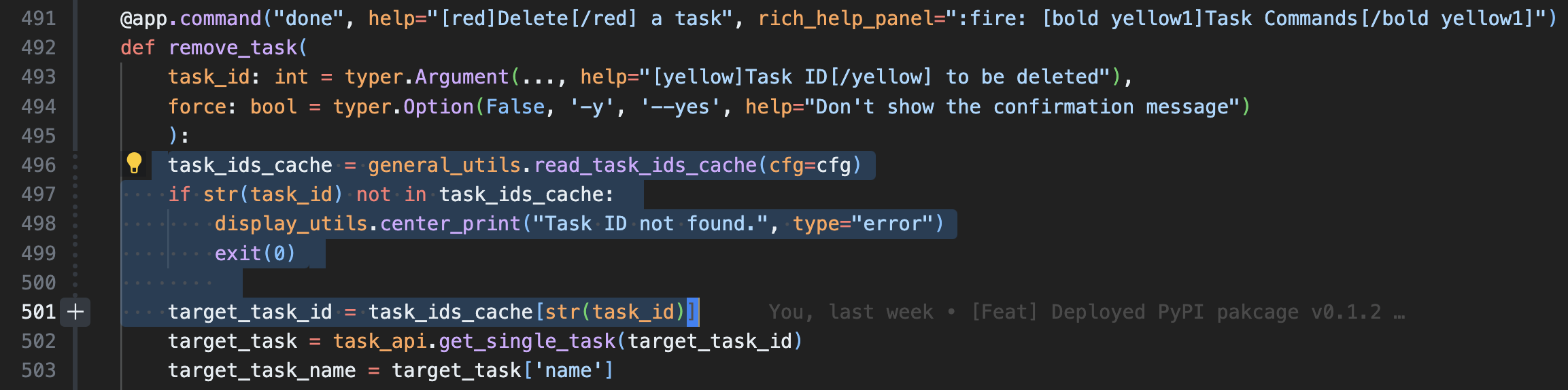
However, in edge cases, some users might perform query twice and use the first query result to perform delete operations. To prevent this, I included a confirmation message showing the task name so that users explicitly see which task they’ll be deleting.
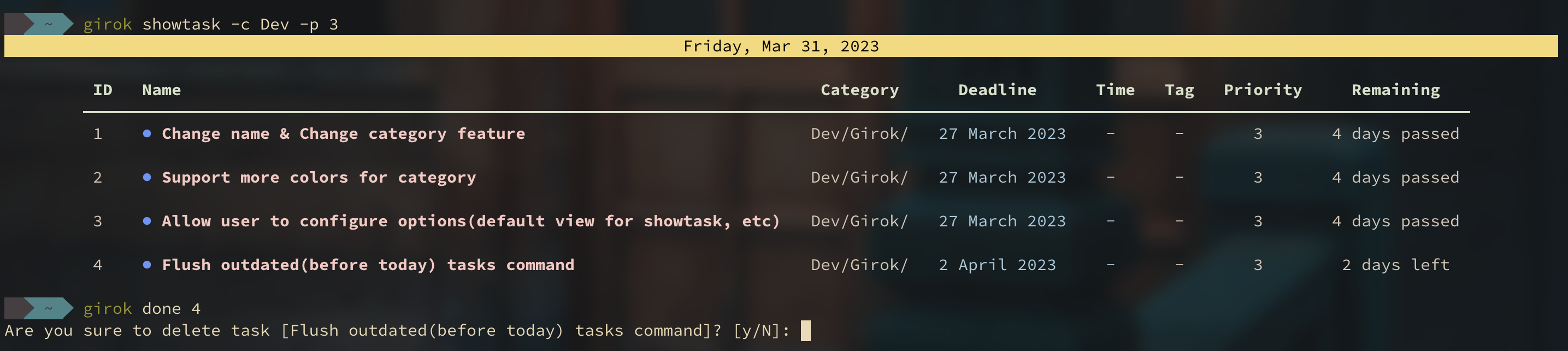
In this way, users would have a reasonable experience without typing task name manually or seeing random and un-ordered task IDs.